Un modelo que conoce tu empresa
ChatGPT sabe de todo y de nada en particular. Nosotros entrenamos un modelo con tus documentos, tus casos, tu jerga técnica y tu tono. El resultado: una IA que responde como respondería tu mejor experto — y nunca inventa lo que no sabe.
Cómo funciona el proceso
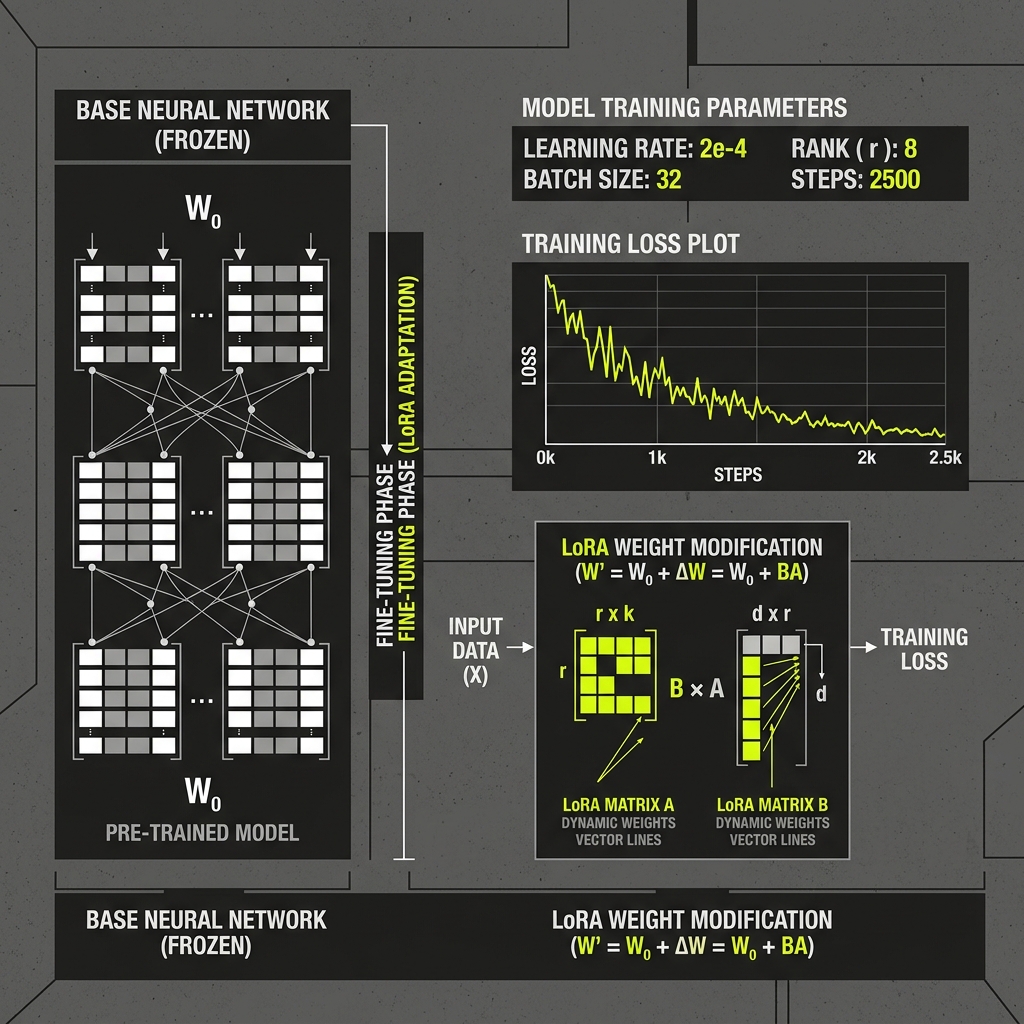
LoRA y QLoRA — sin reentrenar el modelo base
No reescribimos el modelo desde cero. Usamos adaptadores de bajo rango (LoRA) que añaden capas de conocimiento específico sin destruir lo que el modelo ya sabe. Menos GPU, más eficiencia, mismo resultado. Los adaptadores son tuyos — los llevas donde quieras.
Tus datos, limpios y estructurados
PDFs, emails, manuales técnicos, transcripciones, base de conocimiento interna — los procesamos, limpiamos y convertimos en datasets de entrenamiento de calidad. La mayoría de proyectos de fine-tuning fracasan por datos sucios. Nosotros empezamos por ahí.
Evaluación que puedes medir
No te decimos «funciona mejor». Te mostramos los benchmarks antes y después. Evaluaciones automatizadas y pruebas con casos reales de tu negocio. Si el modelo fine-tuneado no supera al base en tu dominio, lo sabemos antes de entregártelo.
Despliegue en tu infraestructura
Cuantización GGUF, optimización de inferencia con vLLM o Ollama, y despliegue en tu servidor. Latencias de producción, sin dependencia de APIs externas. Si OpenAI sube precios mañana, a ti no te afecta.
Modelos con los que trabajamos
Somos agnósticos de modelo. Elegimos según el caso de uso, el hardware disponible y el nivel de privacidad requerido.
LLaMA 3 / LLaMA 3.1
El caballo de batalla. Excelente relación calidad-coste para casos de uso generales. Disponible en 8B, 70B y 405B. Perfecto para asistentes internos y generación de contenido.
Mistral / Mixtral
Eficiente y rápido. Ideal para aplicaciones donde la latencia importa. Mixtral MoE es especialmente bueno cuando necesitas un modelo versátil con bajo consumo de recursos.
Qwen 2.5
Sorprendentemente bueno para código y análisis técnico. Si tu caso de uso involucra razonamiento sobre datos estructurados o generación de código, Qwen merece consideración seria.
¿Tienes documentos que deberían ser un modelo?
Manuales, contratos, historial de soporte, base de conocimiento interna — los convertimos en un modelo IA que conoce tu empresa mejor que cualquier genérico.